
Haussmann, and the future of work
In 1850, Paris was overpopulated, cramped, and full of diseases. By imperial decree, a man named Eugene Haussmann was appointed to fix this problem. In under 20 years, through an unprecedented amount of force - and capital - he shaved off a third of the city and rebuilt it from scratch, making Paris what it is today.
At VZ Labs, our goal is to explore the adjacent possible unlocked by the intelligence revolution. This means two things:
- making new products that were previously impossible.
- doing it in a way that was previously impossible.
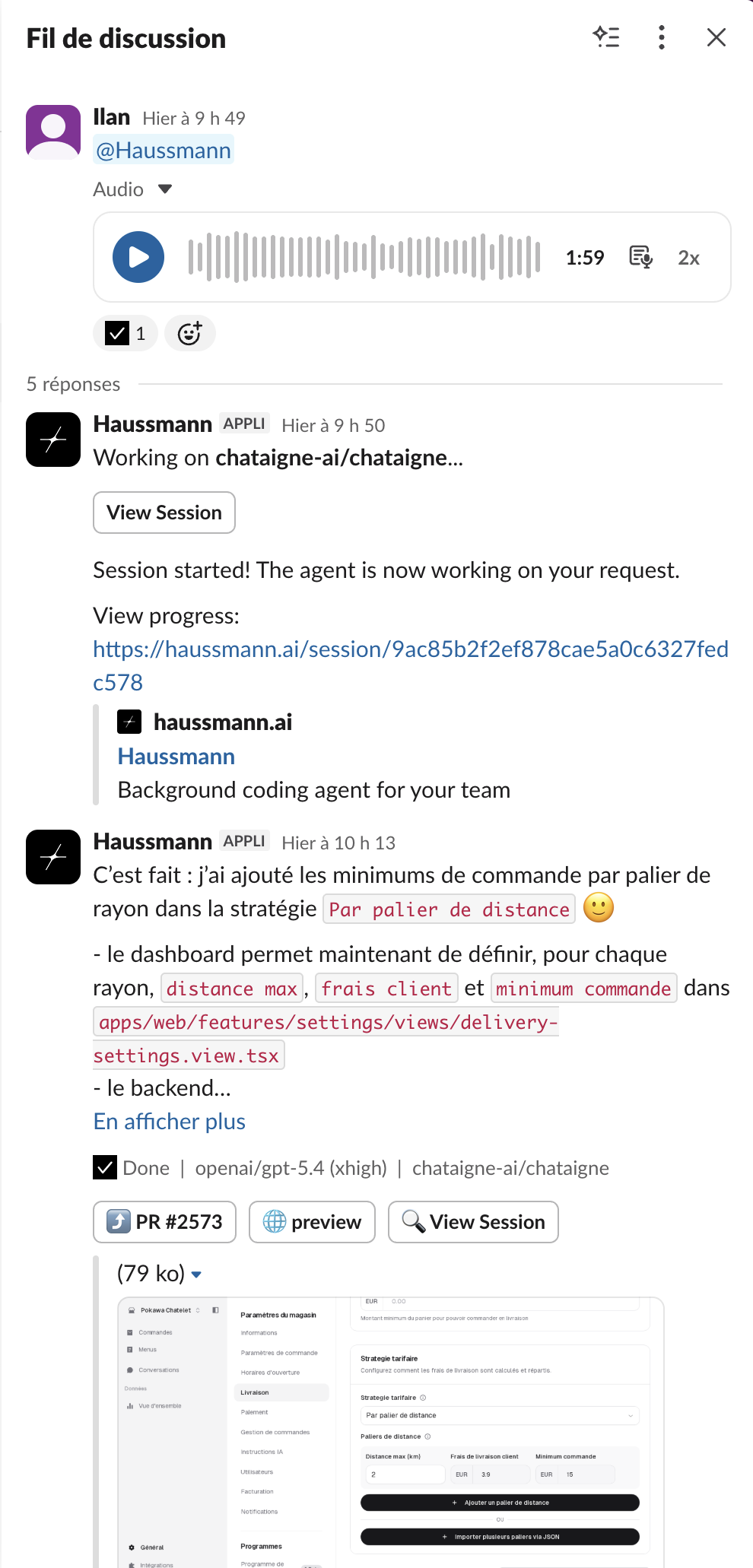
In this post, we'll talk about one of the ways we're doing 2. - Haussmann, our internal background coding agent.
We believe that AI causes such a fundamental change in the nature of man-made work, that the only way to truly embrace this next phase is to tear down what we think we know about work, and build it back up from first principles, akin to what Haussmann did with Paris.
Haussmann has been among our favorite internal tools we have ever built. It has allowed us to move and react at fear-inducing velocity, to compress months into hours, and to have an incredible headcount and capital to impact efficiency.
Making space for monumental work
We believe the first step in AI changing work is effectively taking care of the gut of the distribution of work, letting humans focus on the long tail of high-creativity and high-complexity tasks, where most of the value lies.
What this means in practice - specifically, in an engineering context - is, among other tasks, first taking care of bug investigation and fixes, interoperability (more commonly called "integrations"), and implementation of features that fall within the architectural bounds (pun intended) of the codebase.
So, as good technologists, we went on a quest to automate these away with the tools available to us.
In the first era of agentic coding, we achieved significant speedup by using harnesses like Cursor and Claude Code, but we never managed to reach the threshold of fully autonomous background work. We were held back not by the capabilities of the models but by the pre-AI paradigms of coding, which are now outdated. More thoughts on why → Usually, you pull a copy of your code to your laptop, start working on a branch, run your server and your database locally, iterate, push, and move to the next branch. Now - how do you work on several branches at a time? You really can't. Each branch has its own environment requirements, sometimes its own database schema, and running them all on a single machine quickly becomes impossible. A solution emerged for this, called worktrees - initially an obscure Git feature that gained traction because agents could work on different branches in parallel, each with its own environment. But worktrees come with their own pain: they devour machine resources (your battery does not survive the day), they don't allow truly remote, asynchronous work (you want to be able to close the lid of your computer, right?), and true isolation is genuinely hard. It is hard to let an AI agent run permissionless on the same computer you live on. Put together, all of this means the current paradigm of agentic coding is not adapted to how far we wanted to take it. So we asked ourselves: what if, instead of giving a language model a harness, we gave it a computer? A full computer - its own dev environment, its own seeded database, its own scripts, its own room to make a mess in.
Fully autonomous, asynchronous work was where the real gains could be found, because this implied benefiting from parallelisation - working on many features at a time. Yet the many agentic coding companies weren't able to provide the appropriate tooling for us to get there, to reconcile the dev environment and the agents.
Then, one day, this blog post was released, and we realised we weren't the only ones thinking about this problem, and that the amazing Ramp team had elegantly solved it by simply… doing it for themselves.
It turns out coding environments are very high entropy, and it's incredibly hard to make a product that generalises to all of them. So we built our own, tailored to our environment and our needs.
Put plainly, Haussmann gives any model a laptop. Whenever a session starts, the agent receives a brand new, fresh machine containing our code, plugged into our servers, our logs, our error systems, our database. It is the local environment of a dev on our team, except disposable and infinitely parallelisable - we could spin up thousands of agents at a time, each with its own environment, none of them running on anyone's machine. And each one can do whatever it wants with it.
We built Haussmann because the bottleneck in our workflow was no longer the model or the harness. It was the environment around them: where the agent runs, the tools it has, the feedback it gets, and the way a human verifies what it did.
The problem we kept running into
Most of what we do day to day is bug fixes, customer requests, and operational work. The kind of work everyone agrees matters and that rarely gets the same care as bigger features.
It is also the most disruptive kind. You are mid-architecture and you context-switch into a customer issue, then a production regression. Each task is small. Together they eat the day.
A coding agent on a laptop hits a ceiling fast. The agent needs to launch the full stack, seed data, open a browser, test what it just changed, and iterate. That is hard to do on a single developer's machine, and sharing it across the team so everyone benefits from improvements is nearly impossible. Haussmann started there - too much valuable engineering work sitting in the backlog, the environment around our agents too shallow to take it.
Our bet: the environment is where the leverage lives
A few things were clear before we wrote a line of Haussmann.
Parallelisation is what makes agents useful. Agents take time, and if you can only run one session at once, that time compounds against you. Worktrees help when a task needs heavy human-in-the-loop iteration, but they were too heavy for the kind of background work we wanted to run aggressively - battery, isolation, scale, all the wrong constraints.
Verification is its own bottleneck. Even with a decent PR, a human still has to check out the branch, install dependencies, seed the data, run the app, reproduce the issue, confirm the fix. Reviewing an agent's PR should feel closer to clicking a preview button.
Agents need a real feedback loop. Unit tests help up to a point. What dramatically improves an agent's work is the ability to run the application, click around, inspect what changed, and iterate before handing anything off - pinpointed integration testing, without the cost of an integration test suite.
A surprising amount of the highest-value work also lives outside the repo: logs, traces, production data. An agent with codebase context is dramatically better at this work because it understands how the data was produced.
Models will keep getting better, and so will harnesses. The part that is much harder to generalise is the environment around the model. How you launch your services, how you read your logs, how you observe what the system is doing, how a change moves from prompt to merged PR. That layer is deeply specific to each company, and you cannot buy it off the shelf.
A well-designed environment compounds in value with every new model release. A long context window is only powerful if you have enough quality context to feed it. The companies that move fastest will be the ones that built the right environment for their models to operate in. That is where real differentiation lives, and it is far too specific for any external product to solve for us.
What we built, and why it looks this way
First and foremost, a huge thank you to the amazing open source community we get to stand on the shoulders of. Most importantly, thank you to Ramp's team for Inspect, which inspired our entire architecture and which we reference throughout this article. Thank you to Cole Murray, whose background-agents repo we used as our starting point, and to the teams behind OpenCode and Pi, whose projects we use directly in our stack. It runs on cheap, scalable infrastructure from companies like Modal and Cloudflare. The depth and breadth of the open technical stack today is incredible - we get to stand on it, and focus on our specific vertical.
Prompt from wherever the work starts
For an agent to work in the background without forcing a context switch, you need to be able to reach it from wherever you happen to be when the idea shows up.
Haussmann can be launched from five places today:
- The web app, where we have the most flexibility - model selection, reasoning level, target repo, all the session parameters. This is where we go when a session needs customisation.
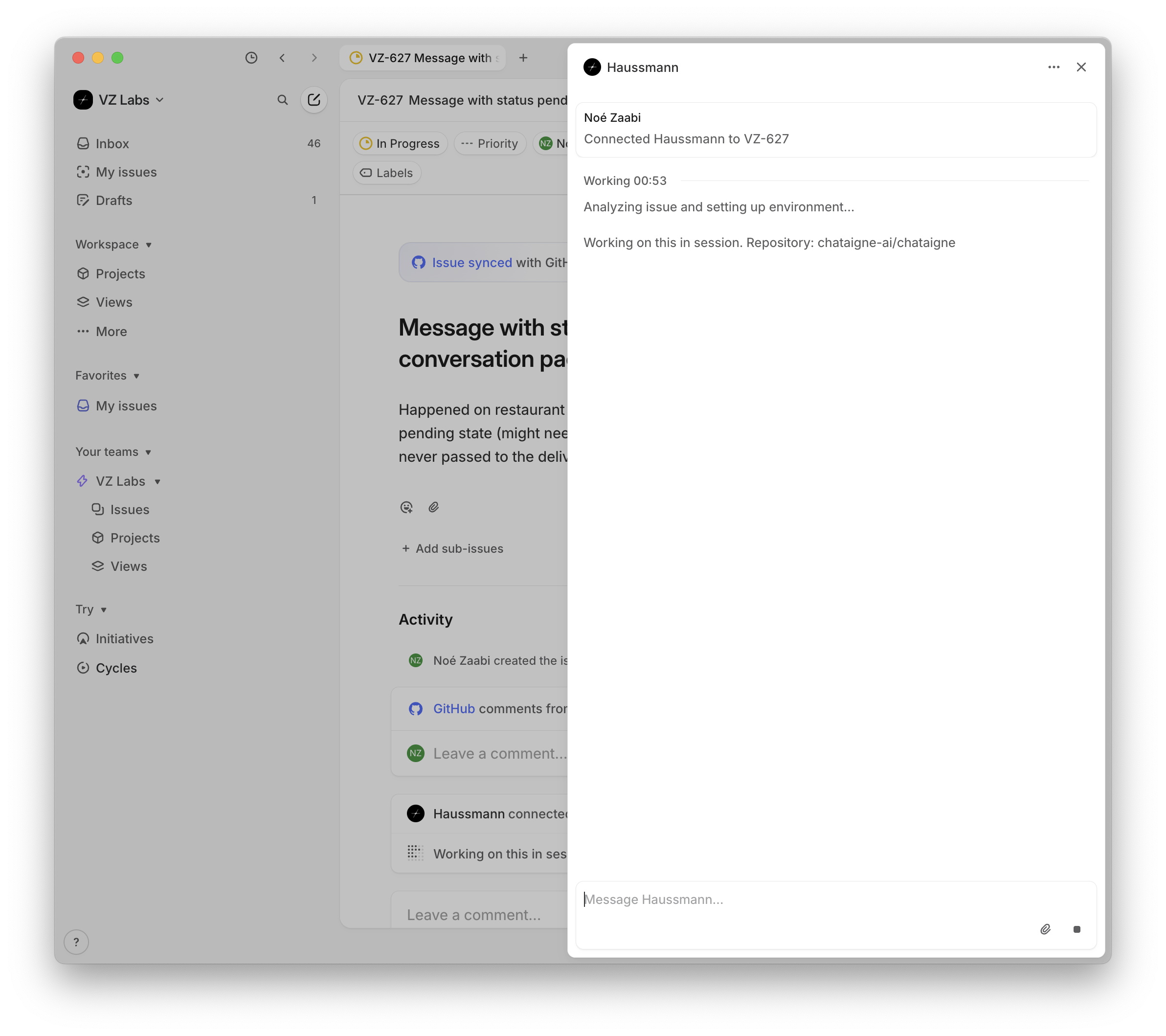
- Slack, where the team collaborates daily and where all our alerts live. It makes it natural to fire off a Haussmann session mid-conversation, to check a number someone just mentioned, or to follow up the moment we agree a feature would be useful. Because we all have Slack on our phones, we get pinged the moment the agent is done.
- Linear, where our backlog lives. You can launch Haussmann directly from an issue. In practice this saw less adoption - turning a one-line ticket into a good prompt still takes effort.
- GitHub, where you can tag Haussmann on a pull request to have it pick up review comments or iterate on the changes directly from the PR thread.
- Aqua, the voice transcriber. I have it set up so that whenever I start a dictation with the word "Haussmann", everything I say after gets piped straight to the agent from my computer. It has quietly become the fastest way I know to launch a session.
We are currently building a WhatsApp integration to make it even easier to launch a session on the go, with a text or a voice note.
Across the first two months: 60.1% of sessions came from the app, 36.8% from Slack, 3.0% from Linear. The interesting signal is the trend - over the last two weeks, Slack alone accounted for more than half of daily sessions. We have gradually drifted toward launching from where the conversation already is.
A dedicated environment per session
Each session is isolated and fast. Speed matters as much as isolation - the moment a session takes more than a few seconds to start, people stop using it for the small tasks, and small tasks are most of the work. Inspired by Ramp's Inspect architecture, we snapshot all our repos through Modal every thirty minutes, fully built, installed, and database-seeded. A session wakes up in about ten seconds.
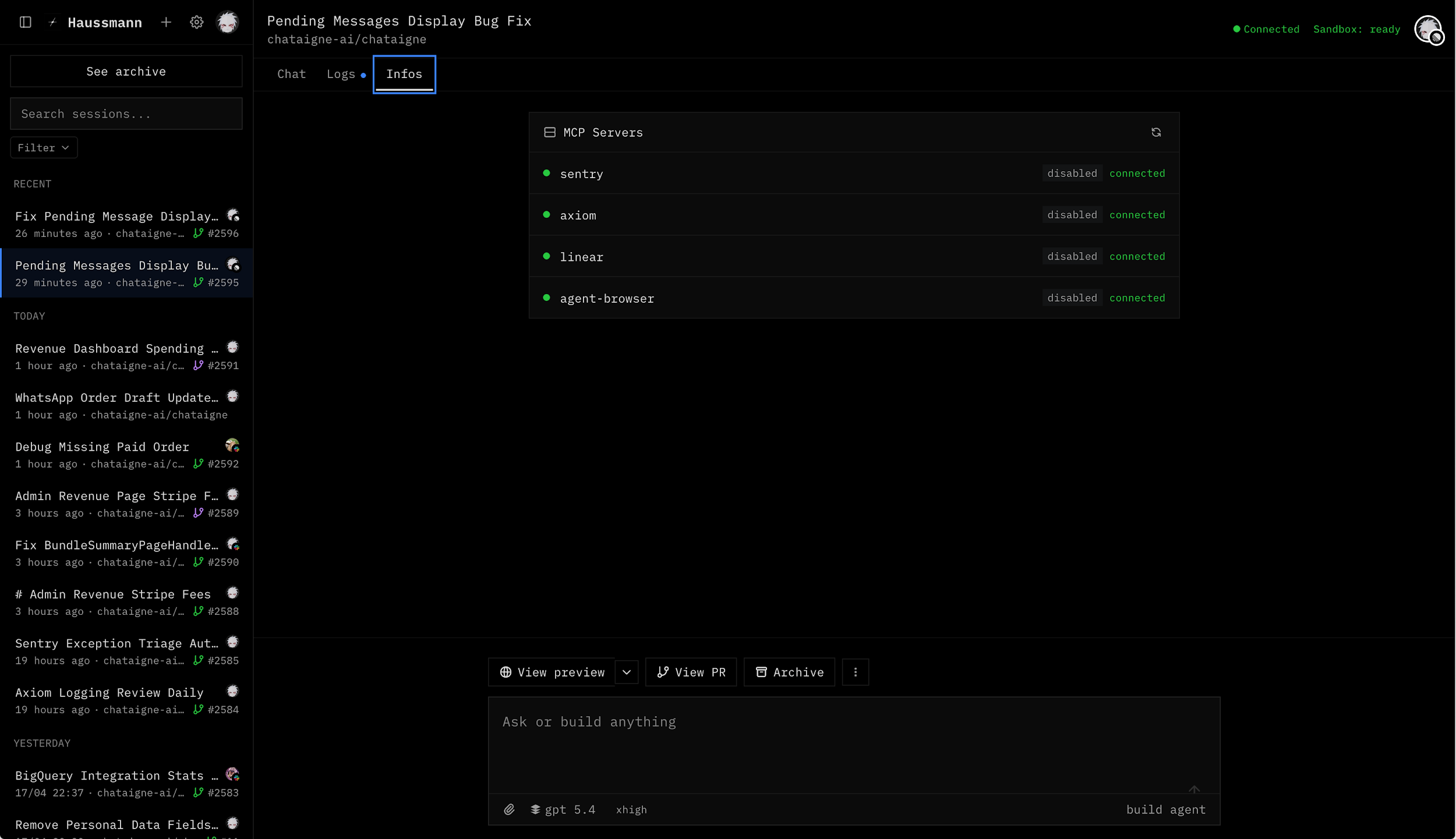
A real feedback loop, built in
Inside that environment, the agent gets the repo, a running stack, seeded data, application logs, testing tools, and a browser. It can mutate sandbox data, exercise the feature it just changed, and iterate before handing anything off.
In practice, the agent changes a piece of UI, opens it in the browser, sees the layout is broken, fixes it, checks again. Or it updates an API endpoint, calls it, looks at the response, tunes until the output is right. Without this loop you are reviewing blind guesses. With it, the agent catches most of its own mistakes before anyone opens the PR.
Review built for humans
Reviewing should not require pulling a branch and rebuilding the world. So we snapshot the Modal instance state before each session shuts down: when someone clicks the preview button on a PR, the sandbox wakes up, services come back online through Modal tunnels, and the reviewer is redirected straight into a live preview of the change.
The agent also uses its headless browser to capture screenshots and record videos of the flows it tested, and attaches them to the PR. Review goes from "check out the branch, rebuild, reconstruct what happened" to "open the PR, watch the recording, click around the preview, read the diff, decide."
If review stays painful, the bottleneck just moves from generation to verification. We have not fully solved this. But making the result visible and testable before anyone opens the diff has already changed how much time review takes.
Access to production context
Haussmann has access to surrounding systems - logs, observability, the database - under constraints. Read-only role, anonymised data, no access to anything sensitive.
This matters for implementation and for exploration. A lot of useful work is just figuring out what is going on - understand a customer issue, review a conversation, check a trace, pull numbers for a product decision. These investigations used to take real engineering time. Now we prompt Haussmann, and a few minutes later we get back the data, plus the codebase context to interpret it.
What the numbers say after two months
Haussmann was deployed internally on February 9, 2026. Here is where things stand after just under two months of use.
Usage. 592 sessions, 183 pull requests created across our repositories. Adoption has been steady, with no sign of plateau. The last two weeks have been the most active: 95 sessions during the week of March 23, 99 during the week of March 30.
PR throughput. Before Haussmann, the team produced 1.7 PRs/day on average. After, that climbed to 5.6 PRs/day - a 3.3x increase. The important detail: human throughput did not collapse. We kept producing around 2 PRs/day, in line with the prior baseline. Haussmann added another 3.4 on top. It did not replace existing work. It made background work cheap enough to actually happen.
Merges. Before Haussmann, the team merged 1.5 PRs/day. After, 3.5 - a 2.3x increase.
Quality. Of the 183 PRs created by Haussmann, 81 were merged, 63 closed without merge, 39 still open at measurement time - a 44.3% merge rate. We do not see that as a failure. A meaningful portion of the closed PRs were exploratory, parallel attempts, or work that became cheap enough to try even without certainty it would ship. The merge rate reflects exactly the stage we are in: execution got much cheaper, but trust and verification are still the hard part.
What actually changed
The most obvious change is that we now launch work we would not have started before. The switching cost was just too high. Haussmann made small work cheap enough to try.
It also changed how we think about the backlog. Instead of waiting for time to tackle something, we launch it in the background and come back to a finished session.
One day, working on an iMessage integration, I pointed Haussmann at a provider's docs and dropped a one-sentence voice note: yeah, go and integrate this. Then I forgot about it. Two hours later, a random iMessage number sent me a message. Haussmann had pulled my number from memory, used it as the test account, and was letting me know it was testing the feature. It even sent me a voice note. That was the surreal moment.
Another came when we gave it access to our production logs. Give an agent full observability and it is remarkably good at finding the root cause - it just goes and finds it. The first time we let Haussmann loose on the logs, it started fixing latency issues, inefficiencies, and a couple of security vulnerabilities, with almost no effort on our end. Wild to watch.
The hard parts are now different
Haussmann did not remove the hard parts. It moved them.
Trust is the new bottleneck. Cheap sessions mean we now launch exploratory work, duplicate approaches, and half-baked ideas much more often than we used to. The question for any session has shifted from whether it is worth trying to whether we can trust the result enough to merge. We produce far more candidates than we can review carefully, and that gap is where most of the friction lives today.
Agents are too optimistic about their own work. They need adversarial systems to catch what they missed. We have started running other agents - Codex, Claude, others - against Haussmann's PRs as a check, but that is a longer story for another post.
There is a monitoring gap. We have no active mechanism today to watch what happens in production after a feature lands. Humans do it naturally - check logs, monitor usage, verify behaviour after a deploy. Agents should be doing it too, calibrated to how sensitive the change is. This is exactly the kind of thing that is only possible when you own the environment, and it would directly help the trust problem above.
Ownership gets messier when execution is cheap. If anyone can start sessions at any time, it becomes easier to create ambiguous work-in-progress, step on someone else's surface, or open changes nobody really owns from prompt to production. Cheap execution makes ownership discipline more important, not less.
What we're exploring now
Better preview environments for third-party integrations. Local app changes are easy to test now, but anything involving webhooks or external systems is still painful. We are building preview environments that interact with the outside world more naturally, so that integrations can be tested end-to-end the same way a local feature is.
Safe operational actions. Read access to production context has already been very useful. The natural next step is letting the agent act on some systems too, not by writing directly to the database, but through constrained APIs with strong permission boundaries. We are looking closely at frameworks like Cloudflare's Code Mode for this. Being a small team, this could let us provide world-class customer support that even much larger human teams could not match.
Cross-session memory. If Haussmann is going to become a real collaborator, it needs to retain and reuse team-specific preferences, guardrails, and lessons learned over time. We are starting to wire this in.
Monitoring as a trigger. Haussmann is wired into our monitors today. Whenever an error fires in production, or a latency spike pushes a service out of normal range, the agent spins up automatically and starts investigating. The reactivity gain has been substantial - by the time anyone on the team would have noticed and opened a thread, Haussmann is already a few steps in. Plainly better, overall.
Multi-agent collaboration. When we first considered this, it felt gimmicky - too many agents, too much orchestration for too little gain. We have changed our minds. Internally, we are starting to see good results from agents handling completely different parts of the company, each with their own tools and their own scope. The open question is whether to unify them into a single entity or keep them isolated. There are real reasons on both sides - security, separation of concerns, and blast radius on the side of separation; shared memory and smoother handoffs on the side of unification. We have not picked a side yet.
There are extremely exciting times ahead. Whatever we build has to be able to benefit from better models as they arrive. We keep asking ourselves: what if models are 10x better? 100x? Most engineering bounds we are tempted to design around will be quietly removed in a couple of years - context windows are the obvious one. So we try not to design around them.
That is why Haussmann fits. It is, at its core, a way to make our environment accessible to AI agents - model agnostic, so as models improve, Haussmann improves with them automatically.
There is much more we will write about in later posts - particularly the workflows we are building around GTM, customer support, and the way we develop AI agents themselves.
If this kind of problem is interesting to you, head over to our careers page. For anything else, you can reach us at [email protected].